
리눅스 wc 명령어: 파일의 단어, 라인, 문자 수 계산하기
wc (Word Count) 명령어는 리눅스 및 유닉스 기반 시스템에서 텍스트 파일의 라인 수, 단어 수, 바이트 수 등을 세는 데 사용되는 명령어입니다. 파일 또는 파일 집합의 내용을 분석할 때 유용하게 사용할 수 있습니다.
☞ 포스트 기준: 리눅스 배포판 CentOS 7
1. wc 명령어 기본 사용법
기본적인 wc 명령어 사용법은 다음과 같습니다:
wc [옵션]... [파일]...2. 주요 옵션 및 설명
| 옵션 | 설명 |
|---|---|
| -l | 파일의 라인 수를 출력 |
| -w | 파일의 단어 수를 출력 |
| -c | 파일의 바이트 수를 출력 |
| -m | 파일의 문자 수를 출력 |
| –words | 파일의 단어 수를 출력 (동일한 기능을 가진 -w와 동일) |
| –lines | 파일의 라인 수를 출력 (동일한 기능을 가진 -l와 동일) |
3. wc 명령어 사용 예시
1. 파일의 라인 수, 단어 수, 바이트 수를 모두 출력하기
wc example.txt위 명령을 실행하면, example.txt 파일에 대해 다음과 같은 출력 결과를 얻을 수 있습니다:
6 12 52 example.txt이 출력은 각각 파일의 라인 수, 단어 수, 바이트 수를 나타냅니다. 여기서 6은 라인 수, 12는 단어 수, 그리고 52는 바이트 수입니다. 마지막 부분의 example.txt는 현재 처리하고 있는 파일의 이름을 나타냅니다.

2. 파일의 단어 수만 출력하기
wc -w example.txt3. 여러 파일의 라인 수 계산 및 총합 출력하기
wc -l file1.txt file2.txt file3.txt4. 표준 입력에서 바이트 수 계산하기 (예: 다른 명령어의 출력을 파이프라인을 통해 wc에 전달)
cat example.txt | wc -c5. 디렉토리 내 모든 ‘.log’ 파일의 단어 수 집계하기
wc -w *.log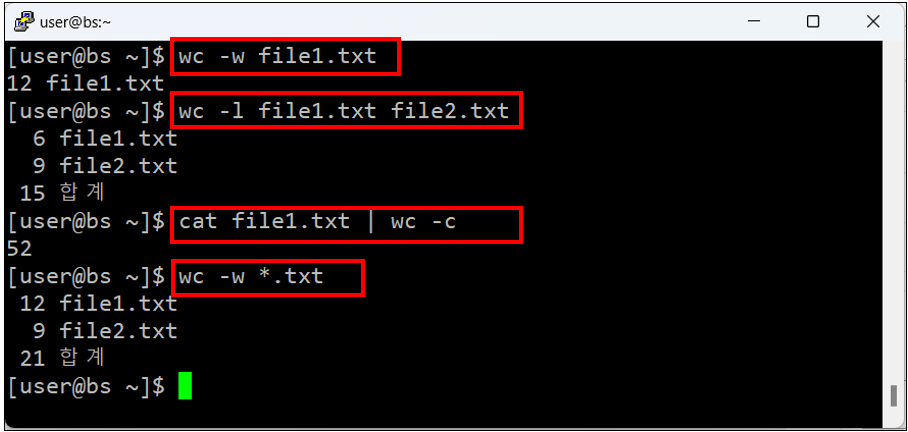
관련 이전 게시글
- 리눅스 cat 명령어: 파일 내용 출력하기
- 리눅스 sort와 uniq 명령어: 텍스트 파일 정렬 및 중복 줄 제거하기
- 리눅스 head와 tail 명령어: 파일의 시작과 끝 내용 확인하기
- 리눅스 more 및 less 명령어: 텍스트 파일 효율적으로 훑어보기
- 리눅스 grep 명령어: 파일 내에서 문자열 검색 및 패턴 찾기
다음 글에서도 리눅스의 기본 명령어에 대해 알아보겠습니다. 이 글이 도움이 되셨다면 공유 부탁드립니다!


