
리눅스 sort와 uniq 명령어: 텍스트 파일 정렬 및 중복 줄 제거하기
리눅스에서 텍스트 파일을 다룰 때, 파일 내용을 정렬하거나 중복된 내용을 제거해야 할 경우가 종종 있습니다. 이때 사용할 수 있는 두 가지 명령어가 sort와 uniq입니다. 이 글에서는 두 명령어의 기본 사용법과 유용한 옵션들을 살펴보겠습니다.
☞ 포스트 기준: 리눅스 배포판 CentOS 7
1. sort 명령어
sort 명령어는 파일의 내용을 줄 단위로 정렬합니다. 기본적으로는 알파벳 순서로 정렬하지만, 다양한 옵션을 사용하여 정렬 방식을 바꿀 수 있습니다.
$ sort 파일명주요 옵션 및 설명
| 옵션 | 설명 |
|---|---|
-n | 숫자를 기준으로 정렬합니다. |
-r | 역순으로 정렬합니다. |
-k | 지정된 필드를 기준으로 정렬합니다. |
sort 명령어 사용 예제
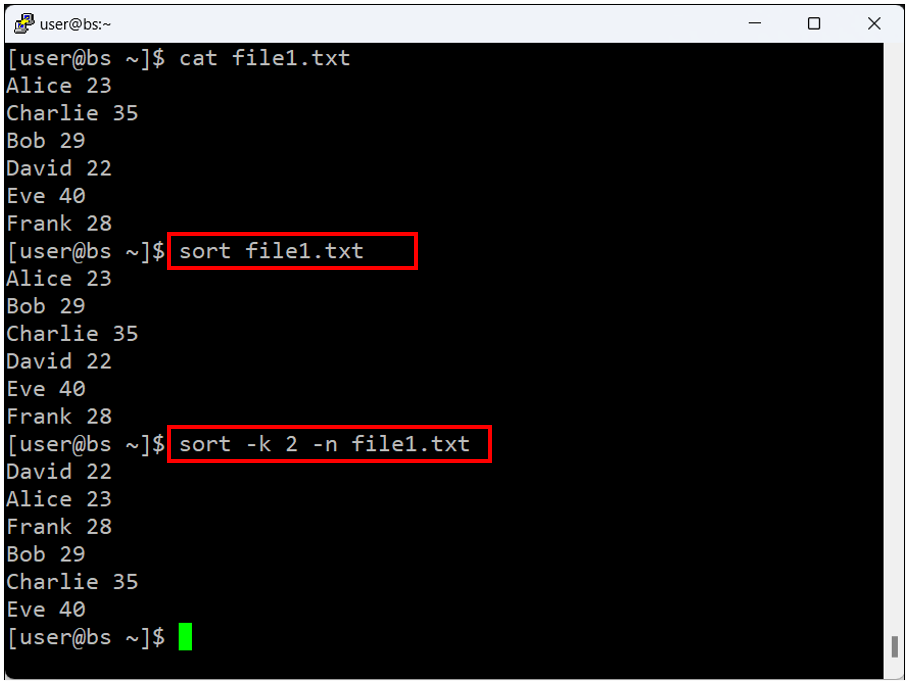
리눅스에서 sort 명령어를 사용하는 기본적인 방법부터 시작해 볼까요? 가장 간단한 형태는 파일의 내용을 알파벳 순으로 정렬하는 것입니다.
sort file1.txt이 명령은 file1.txt 파일의 내용을 알파벳 순으로 표준 출력에 출력합니다. 각 줄을 시작하는 첫 번째 문자를 기준으로 정렬하게 됩니다.
만약 파일의 내용 중 두 번째 열, 즉 여기서는 나이를 기준으로 정렬하려면 -k 옵션을 사용하여 정렬할 열을 지정하고, -n 옵션을 사용하여 숫자 순서대로 정렬할 수 있습니다.
sort -k 2 -n file1.txt위 명령은 file1.txt 파일의 두 번째 열을 기준으로 숫자 순서대로 정렬한 결과를 출력합니다. 이렇게 sort 명령어는 다양한 옵션을 사용하여 강력한 텍스트 정렬 기능을 제공합니다.
2. uniq 명령어
uniq 명령어는 인접한 중복 줄을 제거합니다. 정렬된 파일에서 사용하면 더욱 효과적입니다.
$ uniq 파일명주요 옵션 및 설명
| 옵션 | 설명 |
|---|---|
-c | 줄이 등장하는 횟수를 함께 출력합니다. |
-d | 중복된 줄만을 출력합니다. |
-u | 중복되지 않은 줄만을 출력합니다. |
uniq 명령어 사용 예제
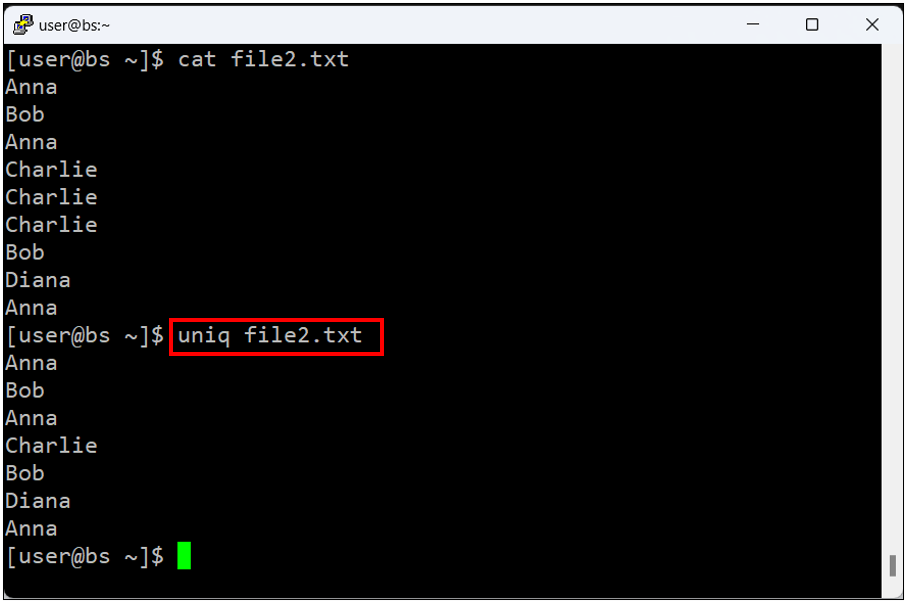
uniq 명령어는 중복된 줄을 필터링하여 출력합니다. 파일 내에서 연속적으로 중복된 줄만을 제거합니다. 따라서 정렬된 파일에서 가장 효과적으로 작동합니다. 아래 예시에서는 ‘file2.txt’ 파일에 있는 중복 줄을 제거하는 방법을 보여줍니다.
uniq file2.txt위 명령어를 실행하면, ‘file2.txt’ 파일에서 연속 중복된 줄이 제거된 결과가 표시됩니다.
sort file2.txt | uniq3. 명령어 사용 예제
다음은 sort와 uniq 명령어를 함께 사용하는 예제입니다.
$ sort 파일명 | uniq위 명령어는 파일을 정렬한 후 중복된 줄을 제거합니다.
만약 중복된 줄의 수와 함께 출력하고 싶다면 다음과 같이 합니다.
$ sort 파일명 | uniq -c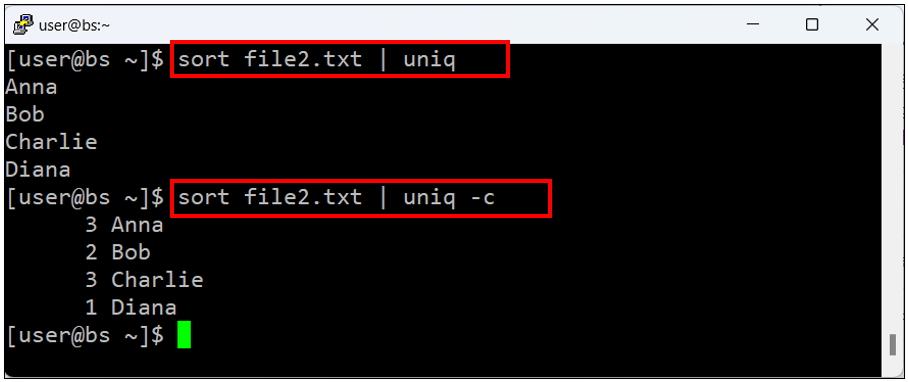
관련 이전 게시글
- 리눅스 cp 명령어: 파일 및 디렉토리 복사하기
- 리눅스 touch 명령어: 파일 생성 및 수정 시간 변경하기
- 리눅스 head와 tail 명령어: 파일의 시작과 끝 내용 확인하기
- 리눅스 more 및 less 명령어: 텍스트 파일 효율적으로 훑어보기
- 리눅스 cat 명령어: 파일 내용 출력하기
다음 글에서도 리눅스의 기본 명령어에 대해 알아보겠습니다. 이 글이 도움이 되셨다면 공유 부탁드립니다!


