
구글시트 IMPORTXML 함수: XPath 활용한 웹 스크래핑
구글시트의 IMPORTXML 함수는 웹 페이지의 XML 및 HTML 데이터를 스크래핑하여 구글시트에 가져오는 데 사용됩니다. 별도의 웹 스크래핑 도구나 복잡한 코드 없이도 XPath를 활용하여 웹 데이터를 시트에 가져올 수 있습니다.
IMPORTXML 함수의 개요
IMPORTXML 함수는 웹 페이지의 XML 및 HTML 데이터를 구글시트로 가져오는 함수입니다. 이 함수를 사용하면 XPath 쿼리를 사용하여 웹 페이지의 특정 요소에 직접 액세스할 수 있습니다.
=IMPORTXML(URL, xpath_검색어, 언어)
함수 설명
- URL: 검토할 페이지의 URL을 입력합니다. (프로토콜(예: http://) 포함)
- xpath_검색어: 구조화된 데이터에서 실행되는 XPath 검색어입니다.
- 언어: 데이터를 파싱할 때 사용할 언어 및 지역 언어 코드를 입력합니다. 지정하지 않으면 문서 언어가 기본으로 사용됩니다.
IMPORTXML 함수 사용 예제
CGV 웹 페이지로부터 현재 상영 중인 영화 제목 가져오기
1. 먼저, CGV의 현재 상영 영화 정보 웹 페이지를 엽니다.
2. 웹 페이지 내에서 개발자 도구(F12)를 연 후, XPath를 활용하여 원하는 영화 제목을 위치시킵니다.
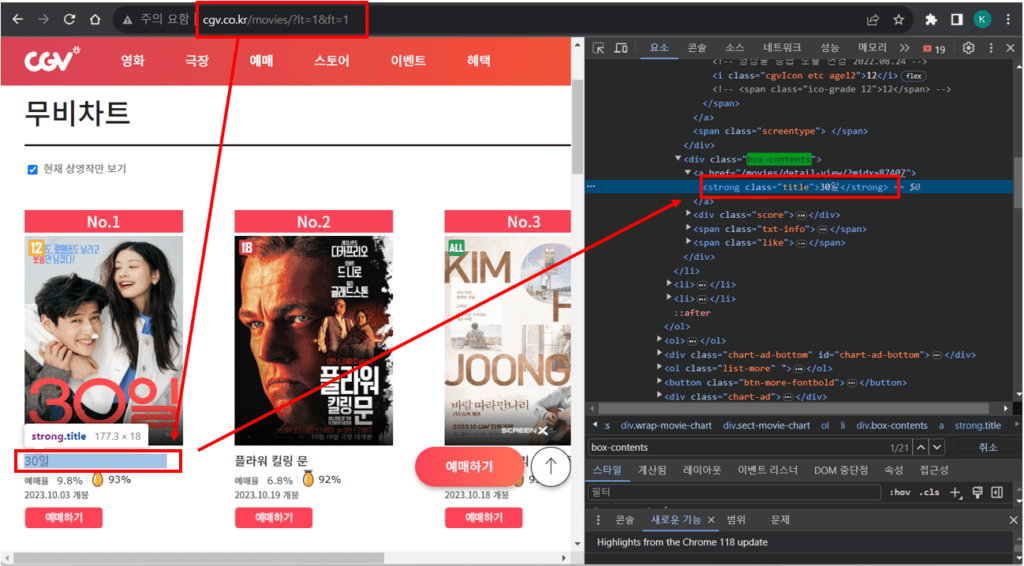
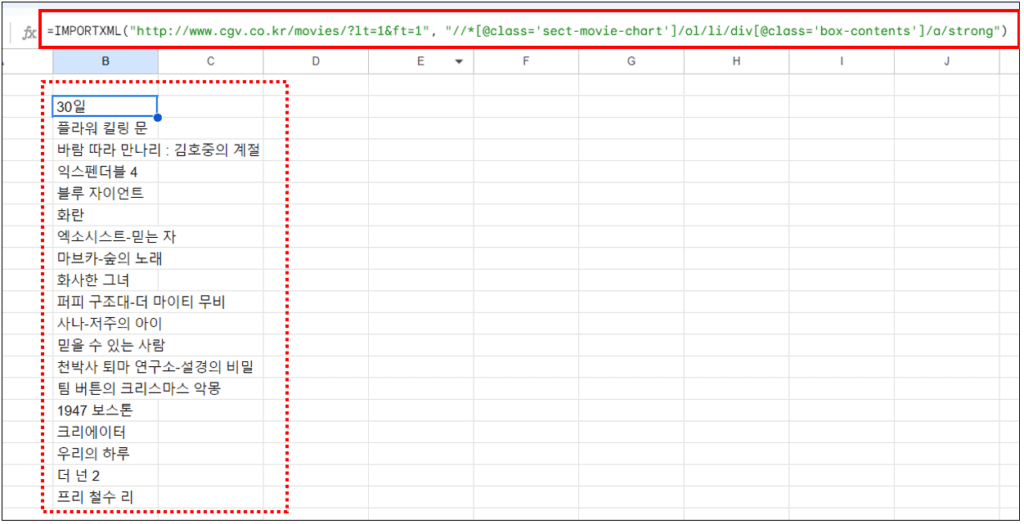
3. 위에서 확인한 XPath를 기반으로 IMPORTXML 함수를 활용하여 정보를 가져옵니다.
=IMPORTXML("http://www.cgv.co.kr/movies/?lt=1&ft=1", "//*[@class='sect-movie-chart']/ol/li/div[@class='box-contents']/a/strong")
참고: 이 함수를 사용하려면 기본적으로 웹 페이지의 HTML 구조를 이해하고 있어야 합니다. 웹 데이터의 변경이나 접근 제한에 따라 동작하지 않을 수 있으므로 주기적인 확인도 필요합니다.
관련 이전 게시글
- 구글시트 IMPORTHTML 함수: 테이블과 목록 웹 스크래핑
- 구글시트 FILTER 함수: 조건에 맞는 데이터만 추출하기
- 구글시트 SORT 함수: 데이터 자동 정렬하기
- 구글시트 UNIQUE 함수: 중복 없이 고유한 값만 추출하기
- 구글시트 SPARKLINE 함수: 셀에 챠트 삽입하기
구글시트의 IMPORTXML 함수를 활용하면 웹 데이터의 스크래핑을 더욱 효과적으로 수행할 수 있습니다. 다음 글에서는 또 다른 유용한 함수에 대해 알아보겠습니다. 이 글이 도움이 되셨다면 공유 부탁드립니다!


